Z Tech|独家解读Meta朱泽园开源新基线,用10%算力跑赢Llama3-8B,科学方法引领新范式,语言模型物理学迈入新时代
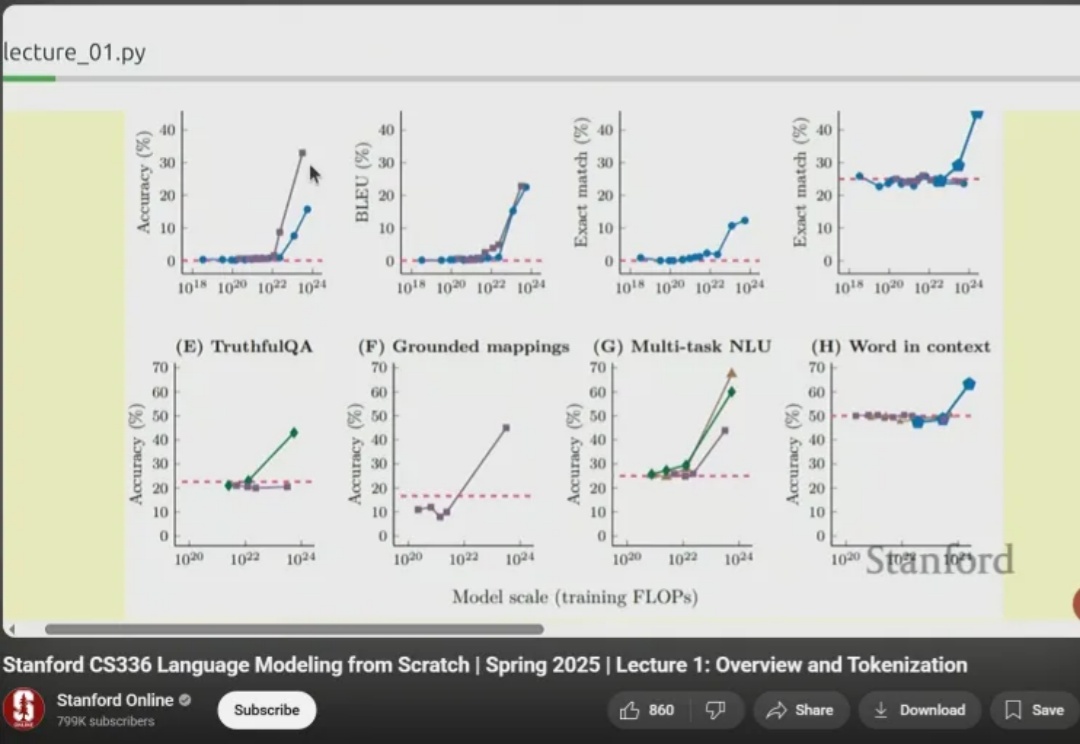
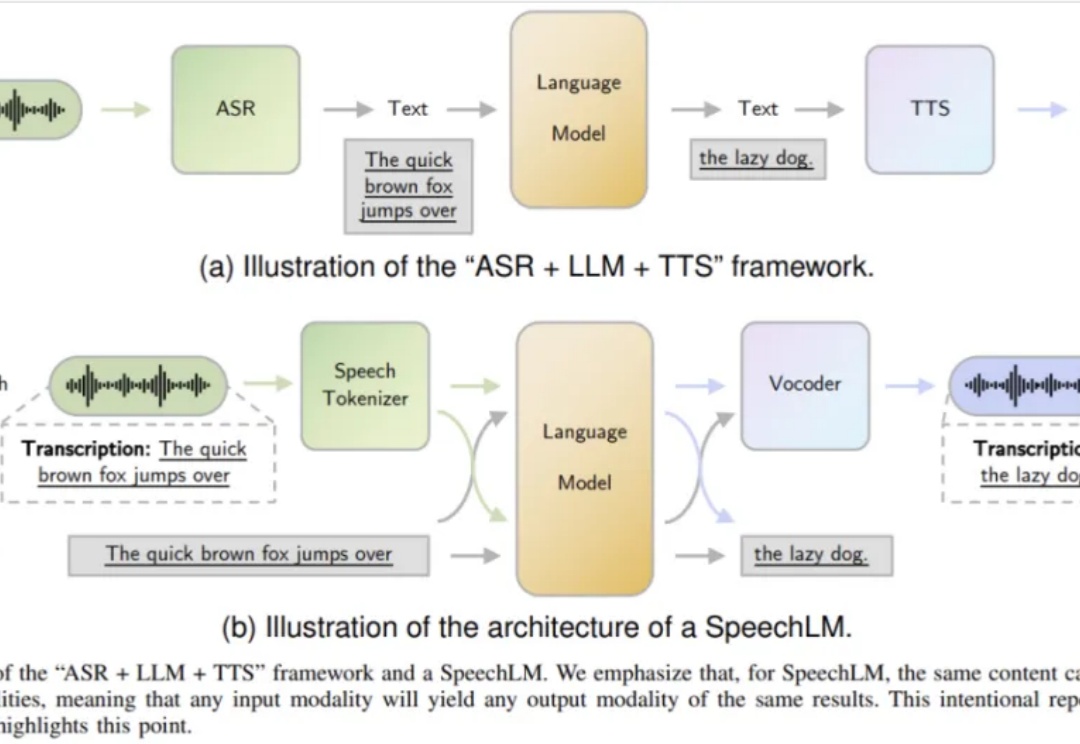
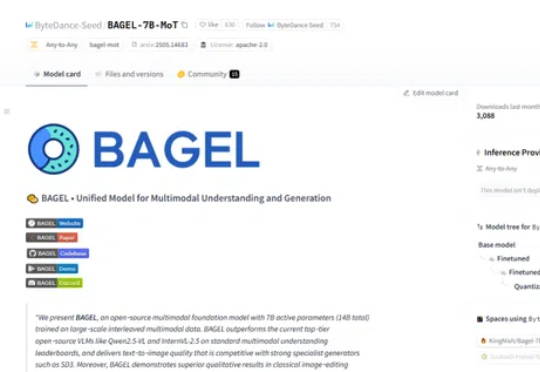
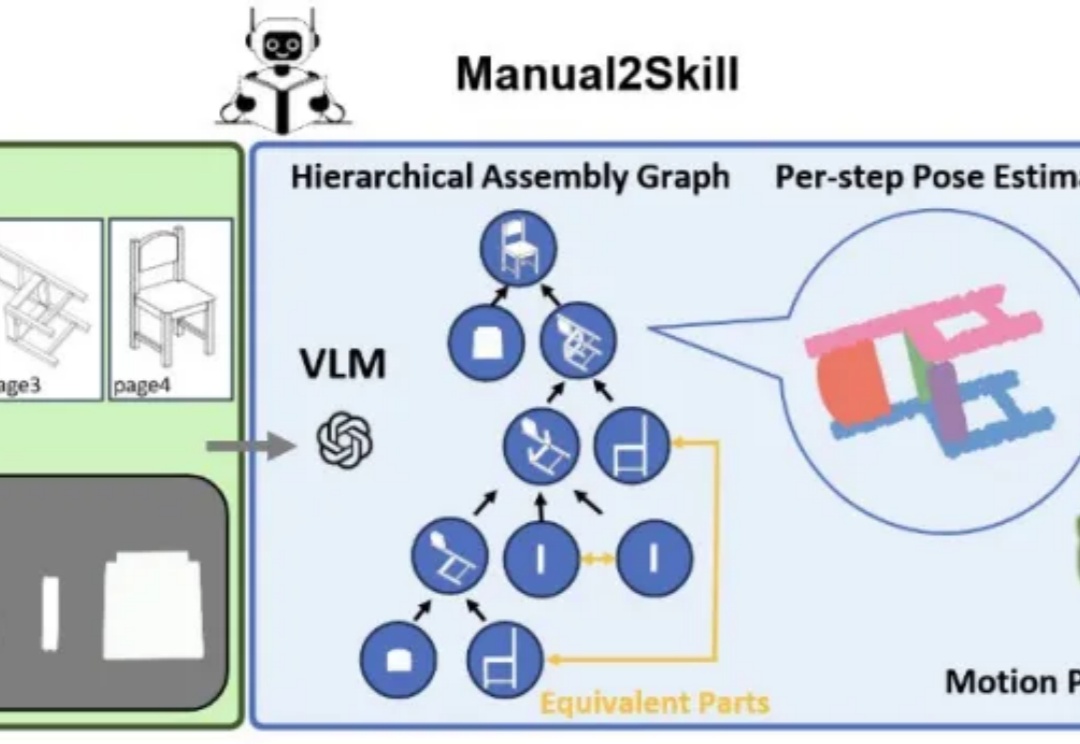
Z Tech|独家解读Meta朱泽园开源新基线,用10%算力跑赢Llama3-8B,科学方法引领新范式,语言模型物理学迈入新时代《Physics of Language Models(语言模型物理学)》,正是将AI研究带入“物理学范式”的项目,由Meta FAIR研究院的朱泽园概念化发起,并统筹设计。
来自主题: AI资讯
8000 点击 2025-08-02 14:04